Hypermedia Online Publishing: the Transformation of the Scholarly Journal
4.3.2 The Internet
Internet overview
In the last few years of this millennium, it has become clear that the world is seeing the emergence of a new way of working with information, based on computer networks and the services they provide. This new information domain is called variously cyberspace, the Matrix or simply the Net. It consists of networks interlinked on a global scale. These networks range from small-scale Local Area Networks (LANs), through cross-organisation Wide Area Networks (WANs) to Global Area Networks (GANs). Some of the GANs, like Digital Equipment's DECNet, are proprietary to an organisation. Others like FIDONet are made up of numbers of small Bulletin Board Systems (BBSs). Others again like BITNet are special purpose research networks. Lastly there are the commercial GANs like Compuserve.
The Internet is a core part of this global network architecture - in a very real sense the ultimate GAN. Originally developed as a way of ensuring the U.S. communications had no single point of failure during the height of the Cold War, it has grown far beyond its research and defence origins. It can now be considered as the 'network of networks', connecting over tens of thousands of separate networks around the world and millions of host machines, many of these being multi-user systems. In Australia, the principle provider of Internet connectivity to Universities and research organisations like the CSIRO is the Australian Academic and Research Network (AARNET). An increasing number of private Internet providers are selling Internet access to the general public.
There are other major WANs that are not based on the Internet protocols. However it is possible to communicate between them and the Internet via electronic mail because of mail gateways that act as translators between the different network protocols involved. As well, large computer companies like Apple and Microsoft are providing built-in Internet access with MacOS8 and Windows 95/98. Many of the more innovative and exciting information services that are being developed at the moment, such as the World-Wide Web, are only accessible on the Internet proper.
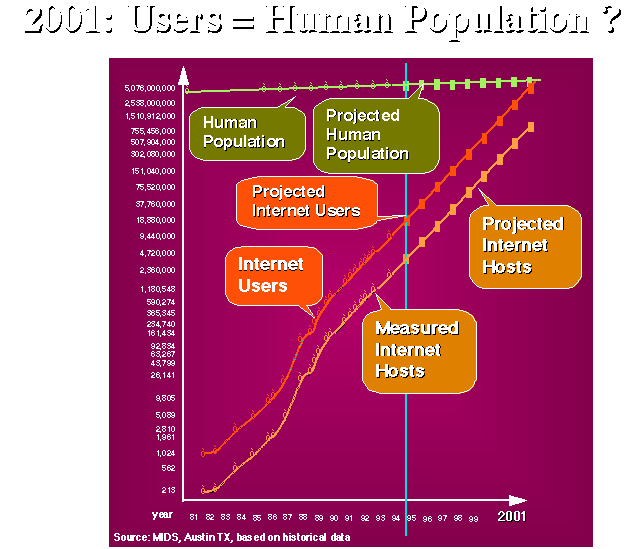
Any numerical measures of the size of the Internet become out of date very rapidly. At the time of writing, the Internet was growing at 100% per year, versus 10% per year for the voice network. Assuming current trends continue, data traffic will overtake voice traffic around the year 2002 [Coffman and Odlyzko, 1998]. At the same rates of growth, the number of users is rapidly converging with the total human population, as shown in figure 4-3. Of course, this convergence will not take place. The growth in Internet users will gradually taper off at some point, but the figure shows just how rapidly the growth is occurring. The hosts shown in figure 4-2 are computers with an IP address that are connected to the Internet. This includes both single-user personal computers and larger multi-user machines.
What most people think of as the Internet can best be characterised by:
Transmission Control Protocol/Internet Protocol (TCP/IP)
TCP/IP is the common name for a family of over 100 data-communications protocols used to organise computers and data-communications equipment into computer networks. As well as its use on the Internet, whose members include universities, other research institutions, government facilities, and many corporations, TCP/IP is also sometimes used for other networks, particularly local area networks that tie together numerous different kinds of computers or tie together engineering workstations.
The Transport Control Protocol (TCP) is responsible for end-to-end links between machines on the Internet. The Internet Protocol (IP) is responsible for connections from one machine to the next on the Internet. Other than TCP and IP, the three main protocols in the TCP/IP suite are the Simple Mail Transfer Protocol (SMTP), the File Transfer Protocol (FTP), and the Telnet Protocol. These three are application level protocols. Together, the TCP/IP family of protocols provides a reliable way of getting information from one computer to another.
IP addresses
In order to identify computers on the Internet, each computer, large or small, which can connect to any of the national networks has its own address or IP number. Each site with a national network connection is given a specific range of numbers that it can use for its internal machine addresses. It is then responsible for allocating this set of numbers within its own organisation. The numbers are in the form of four triplets: for example 128.102.128.50. These are sometimes referred to as a dotted quad. This number identifies a unique Internet machine. This addressing mechanism enables Internet packets to be routed to the correct machine. Note that just because a machine has an IP number does not mean it is connected to the Internet. A significant proportion of TCP/IP networks have no Internet connection at present, although many are implementing such connections.
Domain Names
Because people are not very good at remembering long strings of numbers, machines can also be referred to by their domain names. The Domain Name System (DNS) is a hierarchical, distributed method of organising the name space of the Internet. The DNS administratively groups hosts into a hierarchy of authority that allows addressing and other information to be widely distributed and maintained. A big advantage of the DNS is that using it eliminates dependence on a centrally-maintained file that maps host names to addresses. A Fully Qualified Domain Name (FQDN) is a domain name that includes all the higher level domains relevant to the entity named. For example, for a host, a FQDN would include the string that identifies the particular host, plus all domains of which the host is a part up to and including the top-level domain (the root domain is always null). For example, atlas.arc.nasa.gov is a Fully Qualified Domain Name for the host at 128.102.128.50 (in other words, with 128.102.128.50 as its unique IP number). In addition, arc.nasa.gov is the FQDN for the Ames Research Center (ARC) domain under nasa.gov.
Domain names are typically in the form of machine.site.type.country, although additional sections may be added and some deleted. For instance sol.ccs.deakin.edu.au is a particular machine (sol) in the Computing and Communications Services (ccs) domain of Deakin University (deakin) in the education (edu) domain of Australia (au). Other common domain names are ac (academic - used in the UK), org (organisations that don't fit anywhere else), mil (military), gov (government) and com (commercial). In the NASA example above, the country code is omitted, and hence assumed to be the United States. Most of the country codes are fairly obvious, although Switzerland is ch (from Confederatio Helvetica, the old Latin name) and South Africa is za (from Zuid Afrika).
Most domain names map onto a unique IP number, allowing software to automatically convert from one to the other. Nameserver software is used to manage the databases that match the IP numbers to computer names and locations and make these translations automatically in a way that is transparent to the user. Having machines referred to by domain name also means that the machine that corresponds to a particular name can be changed (for instance to provide more processing power) without users being aware of this. The domain name is redirected to point to a different IP address. Not all machines with domain names are on the Internet. The DNS allows machines on other networks to have domain names to facilitate transmission of electronic mail between networks.
Client-Server
Much of the Internet is organised around the client-server paradigm. Users interact with a client process (usually embodied in a particular piece of software running on a machine they have access to) which communicates over the network with a server process (usually embodied in a separate piece of software running on a remote machine). Crudely put, the client talks to the user, and the server does the work. The interaction between client and server is regulated by standard protocols. This means that many different clients can talk to many different servers, provided they are all talking the same protocols. For instance, an electronic mail client running on a Macintosh (or under Windows or Unix or VMS) can talk to a electronic mail server running under Unix (or under Windows or VMS or Macintosh). Users can use the clients they prefer, and providers can use servers that are the most appropriate in their situation. Ideally in such an environment it should be possible to mix and match clients and servers to best meet the organisation's needs and its users' preferences.
Current developments
At present, the Internet is going through a period of enormously rapid and exciting development. There is explosive growth in the number of users connected and hosts providing information services; and in the range of information services available, and the tools to access these. In parallel with this growth, the user population is becoming more diverse as private service providers expand access to the Internet beyond the traditional academic and research base. Many of these new users expect the same richness and responsiveness in their global networked environments that they see in their other interactions with the computer on their desktop.
In terms of the technology, the Internet is increasingly driven by the emergence of client-server systems, running on heterogeneous hardware and software platforms and using standardised protocols to communicate. The client-server paradigm has become increasingly important to all forms of computing as micro-computers (the preferred client machines) have become more powerful. In the context of the Internet, client-server allows the system designer to place the part of the information system that interacts with the user - the client - on a microcomputer and use a more powerful (and perhaps more user-unfriendly) remote machine - the server - to perform the information processing and retrieval. The proliferation and adoption of desktop machines with a graphical user interface (GUI) allows the client application to use different fonts, colours, and graphics to enhance the interface, as well as to support a wide range of media types.
The client-server paradigm in turn demands well-defined standard protocols to govern communication and interoperability. Fortunately the creation of standards is being facilitated by the push towards open systems across the whole computer industry, with the Internet to some extent being able to piggyback on developments elsewhere. A number of standard protocols have been, or are being, developed for communication between Internet access clients and servers. These include FTP, Telnet, Gopher, Z39.50, HTTP and Prospero. Many of these are de facto standards rather than de jure. The Internet community has observed the extremely protracted gestation of some of the ISO OSI standards, and has drawn the obvious conclusion: technology develops too quickly for such a process to be acceptable. As a result various small groups often develop and propose their own standards for use. Some of these are adopted by others and flourish (Gopher and WWW being good examples); others wither and die. Evolution replaces the committee. This rapid adoption of standard protocols allows the Internet to flourish in a very heterogeneous hardware and software environment. As long as the client or server software adequately supports the necessary protocols, it does not matter much which hardware or operating system is employed. As a result, client and server software for many of the standard protocols can be found for Macintosh, Windows, DOS, VMS, Unix, and IBM mainframe machines.
The information that is being accessed on the Internet is becoming more varied, expanding to encompass digitised photographs, video and stereo sound. Driven by increases in desktop computing power, more capable display devices, and the widespread use of CD-ROM as a capacious (if slow) publishing medium, multimedia has very definitely arrived at the desktop. Even after discounting all the hype, it appears clear that multimedia in some form will constitute a significant part of future access to networked information.
Last modified: Monday, 11-Dec-2017 14:39:19 AEDT
© Andrew Treloar, 2001. * http://andrew.treloar.net/ * andrew.treloar@gmail.com