Hypermedia Online Publishing: the Transformation of the Scholarly Journal
4.5.5 The Web
The WWW project merges the techniques of networked information and hypertext to make an easy but powerful global information system. W3 uses the concept of a seamless information space (the "web"), in which all objects including those accessed by earlier protocols (WAIS, Gopher, FTP, etc.) exist. The project allows information sharing within internationally dispersed teams, and the dissemination of information by support groups. Originally aimed at the High Energy Physics community, it has spread to other areas and attracted much interest in user support, resource discovery and collaborative work areas. It is currently the most advanced information system deployed on the Internet. [Foster, 1994]
The World Wide Web (also WWW, W3, W 3 , or just 'the Web') is the area of fastest growth and most rapid change on the Internet at the time of writing and into the foreseeable future. The most innovative initiatives in information delivery, electronic publishing and electronic commerce are based around the Web and what it offers.
The WWW can be considered as a directed graph of interconnected nodes. Nodes within the graph contain links to other nodes. These nodes are hypertext documents. Hypertext links may point to another location within the same document, or another node (either on the current server, or on a different server altogether). Nodes at the edges of the graph may be stored in many different formats, including plain text, Postscript, graphics (GIF and JPEG), digitised video (Quicktime and MPEG), and sound. Different clients vary in the types of documents they can display. The Web presents users with a document-centred information space. Links in hypertext documents are represented by bold type, underlining or colour highlighting. To follow a link, a reader clicks it with a mouse (if using a Graphical User Interface client) or moves the cursor to it via the arrow keys and presses Enter (if using a screen-based client). Most clients keep a history of links that have been visited, allowing the user to backtrack their browsing. Some documents in the Web are indexes. The user specifies keywords, and the server executes a search. The result of such a search is another 'virtual' document containing links to the documents found by the search. The end result is that the user sees a seamless web of documents. Navigating through the Web is a matter of starting at the right place or following the right links to get there.
Web clients can be used to access a wider range of information services than just Web content. Most provide Gopher support, UseNet News reading, retrieval from File Transfer Protocol sites, and Telnet to other machines. This enables such clients to be used as all-in-one tools for most Internet work. By providing a News or FTP Universal Resource Locator (URL), the client will connect using that access method, and allow the user to navigate around a news server's message hierarchy or through the hierarchies of an FTP archive.
Web internals,
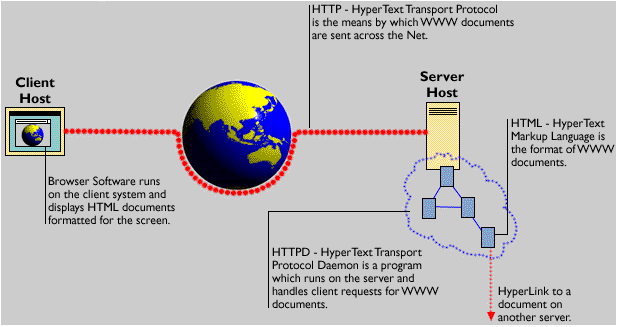
The Web's architecture is based on the protocol used to communicate between client and server (the Hypertext Transfer Protocol - HTTP), the mechanism used to locate resources (the Universal Resource Locator - URL), and the language used to define the hypertext documents (Hypertext Markup Language - HTML). The interaction between client, server, HTML and URL hyperlinks is shown in figure 4-3.
The HyperText Transfer Protocol is evolving rapidly in response to the demands made by new users of the Web. The HTTP protocol assumes a reliable network connection which is typically TCP/IP and in the context of the ISO OSI Reference Model can be viewed as an application layer protocol. The protocol is stateless, and is made up of atomic transactions. Each transaction consists of:
- Connection - established by client to server
- Request - sent by client to server
- Response - sent by server to client
- Close - of connection by either party
Requests may retrieve data, store data, create new documents, make or break links to objects, or ask for a search to be performed.
Because there are so many ways to get to networked information resources, The Universal (or Uniform) Resource Locator (URL) mechanism has been adopted. This mechanism provides a standardised way to reference many resources accessible through the Internet. A URL has the general form of scheme://host.domain:port/path
Scheme identifies an access protocol or method for the object. Some of the defined schemes are HTTP (the native WWW protocol), anonymous FTP, NNTP (Network News Transport Protocol), WAIS, telnet and Gopher.
Host.domain:port specifies the IP address of the host on which the object resides, and optionally the required port. Most Internet services have well-defined default ports which are used if no port is specified.
Path locates the object in a way that is relevant for the access method. For anonymous FTP, this would include the full directory path and file name under which it may be found. For Gopher, the path would be the menu item hierarchy to be traversed. For NNTP, the path would be the newsgroup and unique ID of the news item. For some schemes, the path may include a search string (or combination of strings) that is/are used to address a 'virtual' object formed by searching an index of some kind.
URLs need not be fully qualified. Certain parts of the URL (such as the scheme and machine name) may be omitted, according to well-defined rules. In this case, the URL will refer to another object, relative to the current location. This facilitates movement of linked sets of objects, provided that their relative positions (for instance within a directory hierarchy) are maintained.
Beyond HTML, Web designers can also provide gateways out to other programs. The Common Gateway Interface (CGI) is intended as a standardised way for programs and information services to interact, although at present only HTTP servers are supported. CGI allows for the transfer of data between an HTTP server and a program written in a conventional programming language. Such a program could, for example, interrogate a relational database and return the results to the server for transmission to a remote client. A number of mechanisms also exist for servers to invoke scripting systems such as Applescript on the Macintosh or perl on Unix systems.
Web browsers
A range of clients exist for most of the popular platforms. A line-mode browser, and the full-screen character-based Lynx client are available for many mainframe and mini-computer configurations. Lynx can only display text. Most Web users opt for one of the desktop client packages. The two browsers that currently dominate the market are Netscape's Navigator/Communicator and Microsoft's Internet Explorer (both available for MacOS, Windows, and some flavours of Unix).
The Mosaic and Netscape developers are continually leap-frogging each other in the features their software offers.
Web-based interactivity
The Web offers a number of ways in which content creators can add interactive elements to their documents. The two leading candidates at the time of writing are Shockwave and Java.
Shockwave is the generic name for technology developed by Macromedia (creators of the Director software used extensively by CD-ROM designers). Shockwave delivers Director content (and recently content created using the Flash authoring tool) over the Web using a streaming technology. Shockwave applets can provide moving text, digital sound, interactive buttons, branching program options and animation. To access the content, users need a Shockwave plugin installed in their browser.
Java is a platform-independent programming language developed by Sun Microsystems and designed from the ground up to work in a network world. Unlike other programming languages, Java needs an environment to run in. Java applets run within a browser 'sandbox', a restricted software area within the browser which restricts what they can access and do. Providing the sandbox is implemented correctly, this should be safe for the user with no possibility of malicious damage or access to confidential data. Java applications run with (preferably) OS-level support and have no necessary restrictions; the user can set what the Java environment has access to. Java applets are being used to provide calculation capabilities in Web documents, to enable richer navigation mechanisms, to support embedded simulations and to deliver multimedia content.
Last modified: Monday, 11-Dec-2017 14:38:58 AEDT
© Andrew Treloar, 2001. * http://andrew.treloar.net/ * andrew.treloar@gmail.com