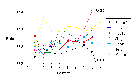
The most commonly used measure of vocabulary richness in statistical linguistics is the relationship between the number of separate vocabulary items - types - and the total number of occurrences of words used - tokens. Thus in the sentence "I am, therefore I think I am" the number of types is 4 and the number of tokens is 7. It is possible to simply divide the number of types by the number of tokens to derive a ratio giving the relationship between the two. This calculation is easy to perform, but makes no allowance for the length of the text from which the counts were taken and therefore makes comparisons between ratios calculated from texts of differing lengths impossible. A preferable calculation, as Gustav Herdan 87 has elegantly demonstrated, is the logarithm of the number of types divided by the logarithm of the number of tokens. This removes the bias caused by changes in text length. It is this ratio that is plotted in figure 25.

Figure 25: Logarithmic Type/Token Ratio Figure 26: Logarithmic Type/Token Ratio Trends As this graph obscures trends over the whole book, figure 26 shows the trend lines for the Logarithmic Type/Token Ratio. These were obtained by the least squares best-fit method. The 'narrator' has been omitted for clarity, and Bernard's anomalous result for chapter IX has not been included in the calculations.
This measure of vocabulary richness only addresses itself to that aspect of the language that may be characterized as its 'repetitiveness': a high score means a low rate of repetition, and a low score means a high rate of repetition. By way of illustration, take the non-sentence "dog dog dog dog dog cat dog dog dog dog". Here only the word "cat" is not repeated. This gives a type/token ratio of 0.4 ( 2 types divided by 10 tokens), and a logarithmic type/token ratio of 0.30103. In contrast take the sentence "The rapid umber vulpine proceeds parabolically over the somnolent canine". Here only the word "the" is repeated. This gives a type/token ratio of 0.9 (9 types divided by 10 tokens) and a logarithmic type/token ratio of 0.954243. This measure therefore makes no attempt to account for such elements as a predilection on the part of the speaker for certain parts of speech, such as adjectives, nor the use of words of Latin derivation in preference to a more common Anglo-Saxon form, nor anything beyond the counting of words. The chief purpose of using it is thus not to quantify all the possible manifestations of a character's language which might be regarded as contributing to its richness, but rather to provide a quantifiable estimate of one aspect of a character's speech which can be used as a firm and objectively verifiable basis for comparison.
From figure 26, one thing stands out clearly. The general trend of all the characters from chapter I to chapter VIII is upwards - that is towards a richer usage of language. This is what one might expect in a book which chronologically depicts the lives of six people through their speech. Their use of language as adults has gradually become richer than as children. Looking at figure 25 in more detail, for four of the characters (Neville, Jinny, Rhoda, and Susan), the richness in vocabulary terms, of their speech in chapter I, is abandoned briefly in chapter II, and more repetition is used. Even though the sentences are longer for these characters in chapter II, they do not introduce as many new words and stay rather with a more restricted vocabulary. Bernard and Louis on the other hand are still innovative in their use of language.
There is also considerable difference between the characters. They do not conform even roughly to a single pattern, with the exception of the general rise noted above, and while over some sections tentative groupings of characters are possible, these do not hold overall. This is strong support for the individuation of the characters.
Lastly, as far as relative overall rankings amongst the characters - or voices, for the 'narrator' is included - are concerned the 'narrator' surpasses the characters in all except chapter IV (surpassed by Jinny) and chapter VIII (surpassed by Susan). By and large the three females come next, followed by the three males with Bernard on the bottom. At first glance this result would seem to go against our intuition; after all, is it not Bernard who is described by himself and others as a phrasemaker? Yet this aspect of his speech does not demonstrate the rich use of language we might have expected. How are we to resolve this contradiction, if indeed it exists? It cannot be argued that Bernard's use of language is unsophisticated and facile. Clearly he does create phrases, and they do have an evocative power. This can be seen most clearly in his masterly summation of the seven lives in chapter IX. At the same time, his low score in the logarithmic type/token ratio shows that his use of language is somewhat repetitive. The answer would appear to lie in the use Bernard makes of this repetition. Rather than being a weakness, the repetition is a vital ingredient in his style, giving his utterances a considered feel, as if he is mulling over what he has said. He also uses repetition to emphasize a point, or to refer back to a previous use of a phrase or word, and thus to bind his discourse together. Viewed in this way, the contradiction disappears. Because of Bernard's unique style, the low logarithmic type-token ratio gives a false impression.


[ Skip to Next Chapter ] [ Table of Contents ] [ E-mail Author ]