Towards a user-centred categorisation of Internet access tools
Andrew Treloar, School of Computing and Mathematics, Deakin University, Rusden Campus, 662 Blackburn Road, Clayton, Victoria, 3168, Ph: +61 3 9244 7461 Fax: +61 3 9244 7460, Email: Andrew.Treloar@deakin.edu.au. WWW: http://www.deakin.edu.au/~aet/Paper delivered at Networkshop '93, Melbourne, Australia, November 29 - December 2, 1993. Last updated June 5, 1996.
Abstract
The Internet provides potential access to a wealth of information, services and resources. Realising this potential requires the use of a range of Internet access tools. In order to facilitate their use of the Internet users need assistance in selecting the right tool for their requirements. Categorising the available tools can provide some of this assistance. Some existing categorisations of these tools have focused on the operation of the tools, the services they provide, or their underlying functions. This paper proposes a categorisation more relevant for users focussed on their requirements, their skills and the demands of the user interface. A number of existing tools are discussed and classified in terms of this categorisation. Finally, some current trends and possible future developments in Internet access tools are discussed.Keywords
Internet, networked information, information access tools, Networked Information Retrieval (NIR), Computer Mediated Communication (CMC), archie, gopher, WAIS, alex, Prospero, Mosaic, ftp, telnet, email.- 1. Introduction
- 2. The user-centred approach
- 3. User-centred categorisation of current tools
- 4. Future developments
1 Introduction
The fastest growing electronic information source ever is without doubt the Internet[1]. The number of computers connected to the Internet, the number of people with access to it, the range of files available, the diversity of information sources and services available all increase daily, with no apparent end in sight. This enormous diversity, spectacular growth, and vast geographical spread have sparked the search for metaphors to convey the feeling of working with it. Some of talked of trying to sip from a firehose, conveying vividly the feeling of trying to deal with a potential torrent of information. Others have used the image of paddling on the shores of a vast ocean. Still others refer to trying to navigate through a poorly mapped forest. Regardless of the metaphor, it is clear that users of the Internet face difficulties in finding what they want or doing what they want to do. These difficulties can arise from barriers to useability within the Internet itself, as well as from problems associated with different Internet access tools.Neuman [1992] lists the following barriers to accessing information on the Internet:
"...it is difficult to identify the information of interest; it is difficult to keep track of this information once found; it is difficult to share information about what is available, or to collaboratively maintain such meta-information; and the information is often scattered across multiple file systems of different types, meaning that different mechanisms are needed to access it."[2]
This is not an exhaustive list, but it reflects the somewhat chaotic nature of a system which has grown explosively and organically over the last twenty years.
1.1 Internet Access tools[3]
Some of the above barriers can be avoided or ameliorated through an appropriate choice of software tools to work with the Internet. This range of software has grown and developed in parallel with the Internet itself, and the complexity of the Internet is reflected to some extent in the tools used to work with it.The difficulty here for the user is to decide what tools are best suited for a particular task. Such a decision may be hampered by ignorance of what tools exist, poor understanding of the task to be accomplished, lack of knowledge of how particular tools interact with particular services, and the like. By way of analogy, if I want to drive a screw into a piece of wood and I only have a chisel can I be faulted for using the chisel to turn the screw. What if I only have a spanner and use it to hammer a nail? Worse still, what if I have two pieces of wood to join together and I don't even know that I can use screws, nails, or glue?
Without some clear guide to Internet access tools, users will choose inappropriate tools, be unable to accomplish desired tasks, give up in despair, or never even start. Conversely, the right tools will simplify and make actual a whole range of possible interactions. The question therefore is how to select the right tool(s) for a particular task.
1.2 Existing categorisations
Selecting the most appropriate Internet access tool is complicated for users by the unclear way in which tools are referred to, and the way in which particular Internet functions can be accessed through more than one tool. As an example of the first problem, ftp (file transfer protocol) can refer to the protocol itself, a client program to enable use of this protocol, a server program which handles ftp requests, or the process of retrieving remote files. As an example of the second, retrieving documents from a remote site can be performed by all of ftp, gopher, WAIS, WWW or through a listserver.A number of attempts to classify Internet access tools have already been made, but all of them are deficient from a user's point of view.
John December (December [1993a]) has proposed an initial division into networked information retrieval (NIR) tools, computer-mediated communication (CMC), and other services. NIR tools include things like alex, archie, gopher, Hytelnet, mosaic, Prospero, veronica, WAIS, World Wide Web (WWW), and WHOIS. CMC includes listservers, email, and Usenet news. Other services include ftp and telnet. December then proposes a detailed and complex notation to summarise the action of each of the tools:
" NOUNS
F File(s)
H Host/computer
I Interface
G Graphical User Interface
L List
M Message(s)
R Receiver
S Server
U User/sender
VERBS
:= has read access only
== has read and write access
:: interacts with user interface (synchronous)
(()) sound in interface
* video interface
<- copys (over network) from
<-> copys (over network) to and from
<+ linked from
<= created by
[] contains
() consists of
CONJUNCTIONS
; and
NOUN PHRASES
S[F] Server containing file(s)
M(L) Message consisting of a List
S[U] Server containing users(s) = other users using this server
H[U] Host containing users(s) = other users logged into this host
NOTATION EXAMPLES:
File Transfer Protocol: U == F <- H[F]
Narration: The user gets read/write access to a copy of a
file that was copied over the network from a
host containing that file
Electronic mail: R == M <- H[M <= U]
Narration: The Receiver gets read/write access to a copy of
the Message that was copied over the network from
an (originating) Host on which resides the original
Message created by the User (Sender)."
This notation has two problems for potential users of these tools who wish to use it to guide their selection (although in fairness it should be pointed out that it was not designed primarily for this purpose). Firstly, the notation can be hard to interpret at first glance and somewhat complex. As an example of the way in which this complexity can lead to confusion, December has only partially categorised ftp (refer example above). Ftp in fact allows users to both get (F <- H[F]), and put (F -> H[F]) files, but this is not reflected in the entry for ftp or in the notation itself. This will be corrected in the next version of the document (December [1993b]). Secondly, the notation provides few clues on which tool to use for a particular purpose, as it is based on the underlying operation of the tools.
Another categorisation is that proposed in Foster, et. al. [1993]. In draft version 3.0 of this report, the taxonomy of tools was Resource Discovery, Class Discovery, Instance Location (indexing), Access, and Information Management. This difficulty with this taxonomy is that it is unclear which services belong where. By draft version 4.1 (the latest at the time of writing), the taxonomy had changed to Interactive Information Delivery Services (things like gopher, and WWW), Directory Services (such as WHOIS and X.500) and Indexing Services (like archie, WAIS, and online library catalogues). While this at least has the advantage of concentrating on the services provided to the users, it is still unclear precisely what tool a user might select for a desired task.
A third division is that contained in Neuman and Augart [1993]. This proposes that the functions of existing Internet information retrieval tools can be divided into Storage, Access, Search, and Organisation. The storage function maintains the data for subsequent access by remote users (either programs or wetware). A range of tools will need to implement the storage function in order to service requests. The access function is how client software reads and writes data stored on a server. This is typically defined by protocols like ftp, or Z39.50. The search function deals with locating data that satisfy particular search criteria. Such searching might be automatically performed by a particular tool in order to satisfy a user request. The organisation function deals with the collection and structuring of information to facilitate retrieval. Examples include directories in anonymous ftp archives or menu structures in gopherspace.
Obraczka et. al. [1993] propose a taxonomy of Internet resource discovery approaches based on the functions provided by the tools (Query/Browse/Organise), the granularity of the objects manipulated, the way in which the information space is organised, how the data is stored, and the preferred interface(s) to the system.
Schwartz et. al. [1992] present another taxonomy based on design choices for both data and meta-data. The axes for this taxonomy are granularity, distribution, interconnection topology and level of data integration.
The problem with all these schemes for categorising networked information retrieval tools is that they reflect an insider's rather than a user's view of the subject domain. They are based either on the internal organisation of particular parts of the Internet (December), an information-science view of information services (Foster et. al.), the underlying core functions (Neuman and Augart), or the internal architecture (Obraczka et. al. - with the exception of the functional division, Schwartz et. al.). None of them help a user to decide what tool to use for what task.
2. The user-centred approach
An alternative categorisation of these tools would take an explicitly user-centred approach, and categorise tools according to a number of different facets simultaneously. This would avoid the difficulties inherent in placing multi-faceted tools into a single group. The decision about what facets to use when performing multi-facet analysis is always problematical. After some trial and error, the facets of user requirements, user interface , and user skills seemed to form natural clusters.2.1 User requirements
This facet deals with what users want to do or achieve. It is the primary determiner of tool for most users. It can be further sub-divided into communication, retrieval, browsing and searching. Some tools will only belong to one category while others will be primarily assigned to one category while having additional entries under others.2.1.1 Communication
Communication here means communication with other people, rather than computer-computer communication (although this will be a necessary part of the underlying technology). The non-Internet analogue of this category would be the familiar technologies of the telephone, paper mail, and physical bulletin boards. This group encompasses all of the areas that December [1993a] lists under computer-mediated communication (CMC).Communication can in turn be further categorised in a number of ways. This paper attempts a division by facets which can be labelled cardinality and synchronicity[4].
Cardinality is viewed from the sender's perspective, as the sender is the initiator of the communication act. It can be classified as either one-one and one-many. One-one involves direct communication between sender and receiver alone. One-many involves direct communication between sender and multiple receivers. Many-many communication can occur over the Internet, but all the current tools assume one user per workstation at any point in time. Thus multiple users sharing a single workstation can be treated as a series of one-many interactions.
Synchronicity can be classified as either synchronous or asynchronous. With a synchronous connection the communication channel between sender and receiver operates and stays open in real time. With an asynchronous connection the channel operates with time intervals between messages, and typically only stays open long enough to deliver the message.
Based on this division, Table 1 shows the sub-categorisation of some of the more popular CMC tools.

Communication is for many users their principal requirement. A close second is often retrieval.
2.1.2 Retrieval
Retrieval means the ability to get information from somewhere remote to somewhere local. As the information is in electronic form, this always means an implied copy, rather than a move. This is different to the non-Internet analogues of retrieval, such as borrowing a book or requesting a journal article, where copying is not necessarily involved.In the past the type of information retrieved was mostly 7-bit ASCII, the lowest common denominator of the Internet. This was later extended to binary data such as program files and non-text data, sometimes encoded to let them move through mail gateways. More recently, standards[5] have evolved to allow the easy movement across hardware platforms of sound, video and graphics data. Some of the retrieval tools only allow the retrieval of documents, while others allow the user to select arbitrary files, regardless of type. In any case, the distinction between document and application is increasingly becoming less clear and less important to many users. Common retrieval tools include ftp, alex, gopher, WWW and WAIS.
Ftp and alex both allow the user to navigate through directory hierarchies on a remote machine and get[6] files to a local machine. Ftp distinguishes only between text and binary files. Binary does not necessarily refer to the file's original form - many binary files are encoded as text and stored on ftp servers. Macintosh files are a good example of this; due to their unique file format, they are usually encoded as text in BinHex format for storage on non-Macintosh servers. Anything from sound to video to graphics to application programs may be stored and retrieved as binary data. Gopher (Wiggins [1993]) allows the user to retrieve files once located in a gopherspace menu. Again, these files may be text, binary, or encoded binary. WWW (see below), while primarily a browsing tool can also be used to retrieve files. WAIS (Kahle et. al. [1992]) is primarily a searching tool. However, once a document is located, it can be retrieved to a local machine. WAIS documents are usually text files, but may also be sound, video or graphics documents. WAIS servers do not usually store binary application files.
Retrieval assumes the user knows what they want to retrieve and/or how to get there. Users locate the information they want by being told about it (electronically or in print form), by browsing information spaces, or by executing an electronic search. Direct information about the location of a file need not be discussed here. Browsing and searching will be considered separately.
2.1.3 Browsing
Browsing refers to the ability to navigate through an information space looking for items of interest. This is somewhat analogous to browsing along the shelves of a bookshelf or library. Browsing tools typically do not offer any search facilities, although some are starting to add this capability. Rather they rely on the underlying organisation of the information space to inform the user's movements. Browsing tools include World Wide Web (WWW), Mosaic, Gopher, ftp and Hytelnet.World Wide Web (Berners-Lee et al. [1992]) is a distributed hypertext system. Users select links which might point to another directory on the current machine, another machine on the same campus, or a machine on the other side of the world. As in other hypertext systems some users may become disorientated or be unable to find what they are looking for. WWW can also be used to retrieve documents in some client implementations. Mosaic from the National Centre for Supercomputing Applications is based on the WWW model, but also provides gateways to other services, such as NetNews and ftp, as well as excellent multimedia support. Gopher offers access to files and interactive systems using a hierarchical menu system. Users navigate through menus to locate resources, which may include documents of various types or telnet sessions. Ftp can also serve as a browsing tool, although in a somewhat user-hostile way. Users can navigate around the directory hierarchy of the ftp server as a crude way of locating items of interest. Hytelnet (Scott [1992]) provides a hyper-textual catalogue of services on the user's local machine. Users can browse this catalogue to locate services and then follow the supplied instructions to access those services.
2.1.4 Searching
Searching should be clearly distinguished from retrieval. Retrieval means getting something once the location is known (although the location may be found by browsing - Gopher is particularly amenable to this). Searching involves asking a question and receiving an answer. Searching tools can best be categorised by the type of object that is the subject of the search. This may be people, files, servers or services.Many users want to search for people, and by extension for some form of contact information. Here the question involves supplying some identifying information with the answer being an email address, or possibly full contact details. Tools that support this are X.500 (named after the protocol of the same name), WHOIS, and Netfind. X.500 is a directory service that has been under development for a number of years. Ultimately it is intended to use X.500 to provide an Internet-wide distributed directory of users. WHOIS relies on a database of registered network names that is local to an organisation. WHOIS servers do not share a common directory with other WHOIS servers, nor do they know where to locate information about other institutions. Netfind attempts to locate information about Internet users based on their name and some approximate location information. Netfind does not maintain a directory but searches for people using a number of Internet services and heuristics.
Users may also want to locate files, particularly files stored at anonymous ftp archive sites. Due to the number of possible sites, and the range of files stored, searching is often the only feasible way to locate such files. Archie provides access to a database of anonymous ftp files stored at sites worldwide. It thus complements the ftp retrieval service discussed above. The question asked is of the form 'locate a filename containing these characters'. While it is possible to specify quite precisely the exact sequence of characters, it is only the filename (including directory path) that can be searched for. What is returned is a list of site names that have the file, together with the necessary directory path for each site. This means that archie is very good for locating a file once the name is known. It is much less useful for locating files in a particular subject area, such as graphics, or files containing particular words. WAIS (Wide Area Information Server) on the other hand indexes the contents of text files. A WAIS search consists of specifying words or phrases, perhaps combined with boolean operators. It is also possible to ask a WAIS server to look for documents that are 'similar' to a specified sequence of text. The answer in either case is a list of document titles. Each document can be retrieved if desired.
Users may have an idea of what they want to search for, but be unsure of where to ask the question. Two tools allow users to search for servers: veronica and WAIS. Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerised Archives) is a sort of 'archie for gopher servers'. Veronica allows the use to search for particular words in the titles of gopher menus, thus facilitating the correct choice of gopher server. WAIS requires the user to specify a server or servers that will provide the answer to a particular question. It is possible to use WAIS to first search for servers dealing with a particular area before running a specific question against those servers.
Finally, users may wish to locate particular Internet services that are difficult to classify. At present there are few tools to assist with this task. Users must either browse through Hytelnet or refer to other sources of information, such as the Yanoff list, the alt.internet.services newsgroup, or the Network Working Group document Internet-treasure.txt (RFC 1402).
2.2 User interface
This facet deals with the interface the user will be required to manipulate in order to use the tool. Many Internet access tools come in command line, screen-based, and GUI versions.Command line tools often have originated in the Unix world, where they are a standard way of processing information. Typically, the user types a one-line command which invokes a tool and supplies it with some arguments. The command performs the requested task and fills the display with a scrolling list of returned information. Usually there is little or no attempt to use the display as more than an infinite sheet of paper. Most archie searches are a good example of this approach.
The screen-based tools assume some form of terminal, usually a VT-100, as their display. Information is displayed using bold text and reverse type where appropriate. The user may enter commands, press particular key combinations, use the arrow keys to move around the screen, or a combination of all three. The tool will use direct addressing to provide a more sophisticated display than that found with a command line tool. These tools operate adequately over slow serial lines, and provide surprisingly good functionality. The client program may run on a local multi-user system or on a remote system accessed via telnet. Most newsreaders (and some mail programs) on multi-user systems are good examples of this type of tool.
The GUI tools typically operate under X-Windows, the Macintosh Finder, or Windows. They provide all the display/useability facilities one would expect, including multiple fonts, colour, and graphics. Users may enter text, click on buttons, drag icons, and select menus. These tools typically require TCP/IP communications and run on local personal computers or workstations. They are generally preferable to screen-based tools due to the richer interface and greater ease of use.
In addition to the question of interface, there are also necessary low-level operations. These include selecting options, entering commands, mousing around, and entering text. As these operations are obvious and so closely linked to the interface for a particular tool, they will not be discussed further.
2.3 User skills
This facet deals with what users have to be able to do to use a particular Internet access tool. Such skills include logging-in, navigation of hierarchies or hyper textual links, entering search expressions, and categorising information.A number of tools require the ability to log onto a remote machine, either as a registered user, or as an anonymous guest. Telnet usually requires that you have an account on the remote machine, but a number of Internet services can be accessed by telnetting to a remote machine and logging on with a particular username, such as 'archie', 'netfind', 'www' and the like. Anonymous logins are usually required for access to anonymous ftp archives.
The idea of hierarchies is inherent in most of the file systems used on computers across the Internet. Perhaps for this reason, as well as others, hierarchies are a very common way of organising networked information. Gopherspace is usually structured into hierarchical menus. Ftp archives are built on top of the underlying file systems and therefore inherit their hierarchies. Alex systems are built on top of ftp archives and therefore do the same. Even Usenet news is organised into hierarchies by subject matter, so that one gets trees of multiple levels (i.e. comp.sys.mac.digest). This all has at least two implications for users. Firstly, users need to be able to navigate down, up, and across these hierarchy trees to access information. It is possible to treat an ftp path like a sequence of magic words that takes one to the right spot, but then one has no sense of one's location in the overall scheme of things. This makes moving to another location in the hierarchy very inefficient. The second implication is that users need to be able to keep track of their locations in very large hierarchies. The University of Michigan Macintosh archive is carefully organised into neat hierarchies by subject, so that one gets paths that look like 'mac/misc/game/arcade'. When this archive is accessed via alex, the path becomes 'alex/edu/umich/mac/mac/misc/game/arcade'. This is getting close to the limits of most user's short-term memories.
Hypertextual systems, particularly those built around the World Wide Web, require the user to be able to follow links. This is not so difficult, but after a number of links users frequently feel disorientated and unable to find their way back. Perhaps this is the result of hierarchical conditioning, but many users feel uncomfortable navigating around a multiply-connected graph.
For searching, users need to be able to enter their search expressions in the correct form . If this is a single keyword or sequence of characters (such as in a simple archie search) then there should be no problems. If the search requires a complicated character pattern according to the 'regex' rules (as in a more complex archie search), or a combination of keywords with boolean operators (as in a sophisticated WAIS request), then users may make mistakes and not retrieve all of the relevant information. As well, Internet tools do not operate with a controlled vocabulary, and it may be necessary to try a number of different keywords/character sequences. There is also no easy way of determining the rates of recall or precision of such searches.
Finally, users need to be able to categorise the information they locate. This is particularly so with tools that retrieve files or documents. If the document is plain text, then most systems should be able to work with it (although Mac, Dos and Unix all have differing conventions for text file format). If the document/file is of any other type, the user may be required to further process it before use. Users need to be able to determine whether binary or text ftp transfer is appropriate, whether the file has been compressed/encoded (and if so, what program to use to uncompress/ decode it), or if the information is even in a form that they can use (there is little point in a Macintosh user retrieving a Dos executable file). Fortunately, a number of tools are moving towards providing automatic translation/processing of files where appropriate, and cross-platform standards are slowly being codified and used. Mosaic, for instance, uses the MIME content type information to determine the appropriate decoder/viewer to use for a retrieved file, and if this fails examinines its extension (.ps, .gif, .z, .hqx, etc.).
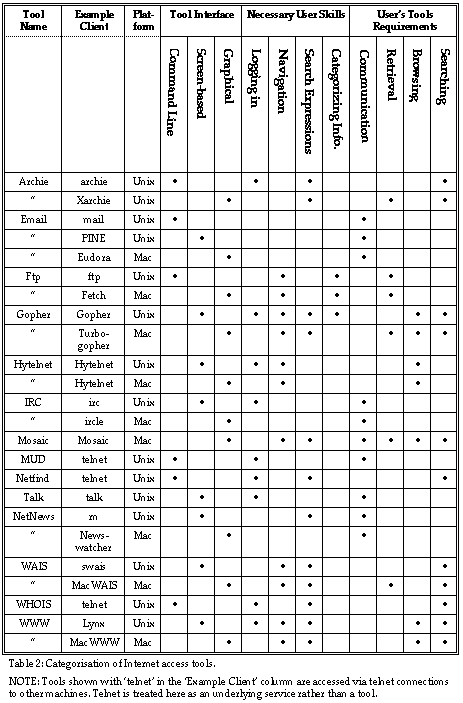
3. User-centred categorisation of current tools
Based on the above discussion, it is possible to use this categorisation to analyse a range of popular Internet access tools. The results of this exercise appear in Table 2 (at the end of the paper). A given tool may support a range of user functions at the same time; in this case the table tries to identify each of these. The table attempts to list both general tool categories (such as 'archie') and specific implementations of clients for these tools. These implementations are indicative only, and are not intended as an exhaustive list. Indeed, given the rate of growth in production of new tool types and different clients for these tools, an exhaustive list would either be impossible to create, or once created become almost instantly out of date.The columns in Table 2 have mostly been discussed already, and will not be considered further. The only exception is the 'Platform' column. Again, this is not intended to be exhaustive. It indicates only one of a number of possible platforms on which a given client may run. For example, implementations of Mosaic are available for Macintosh, Windows, and X-Windows. The table does attempt to provide one example for each of the three different tool interface categories. Where no such entry appears (as for instance with the lack of a screen-based MUD client) this should not be taken to mean that no such client exists. The table simply reflects the level of the author's knowledge at the time of writing[7].
Note that different tool implementations may support different functions. As an example, the standard archie client allows for searches of the archie database only. The X-windows archie client also allows for automated retrieval (via ftp) of files once found.
The intention behind this table is that a user can use the columns under 'User's Tool Requirements' to select an appropriate set of tools for their requirements. s set can then be narrowed by selecting the preferred 'Tool Interface'. Finally, the 'Necessary User Skills' columns provide an indication of what will be required from the user in working with these tools.
4. Future developments
It should be clear from the above categorisation and associated discussion that more work is needed in the area of Internet access tools. Improvements are required in the areas of integration, richness and standards.At present, working with many of the tools discussed in this article can be a very frustrating experience. Many of the tools operate at a low level and require a degree of skill and persistence. More importantly, different tools do not integrate well with each other, even when they operate in the same area. For instance, with most implementations of archie (xarchie is an exception) there is no easy way to pass the results of an archie search to an ftp session to simplify the retrieval of the desired files. This seems inexplicable as archie is specifically designed to support anonymous ftp. One welcome trend of late has been the appearance of gateways in one tools to services provided by other tools. This is an improvement, particularly when handled in a transparent way. Mosaic, for instance, provides gateways to Gopher, WAIS, USENET News, and FTP.
The second area of improvement is in support for multimedia and richer document types. Driven by increases in desktop computing power, more capable display devices, and the widespread use of CD-ROM as a capacious (if slow) publishing medium, multimedia has well and truly come to the desktop. Even after discounting all the hype, it appears clear that multimedia in some form will constitute a significant part of future desktop interfaces. Witness the recent release of the Apple AV range of desktop computers, sporting integrated video capture, the Plaintalk speech recognition and generation technologies, and built-in CD-ROM. The creation of documents containing more than plain ASCII text has been commonplace for years, and current word-processors contain facilities for adding voice annotations to text. For many users these new developments are opening their eyes to the inherent visual poverty of the monospace, monochrome text that has been so prevalent for so long. Unfortunately, many Internet services and tools assume the lowest common denominator of 7-bit ASCII. This is partly tied up with the need for standards (about which more below), and partly the lag while tools are developed. Some developments in the right direction are the new MIME standard as a way of providing multimedia email documents by building on top of existing email protocols, the increasing use of Postscript as a standard (although non-editable) document interchange format, and cross-platform graphics standards like GIF. Many tools are starting to include support for richer document types. Mosaic, for example, attempts to provide support for as wide a range of document types as possible by drawing on external document viewers. This is an approach with much merit, as it allows the user to choose the viewers that they prefer.
The third area of improvement is in the area of standards. These are particularly important in the areas of protocols and document interchange. Fortunately, the creation of standards is being facilitated by the push towards open systems across the whole computer industry, with the Internet to some extent being able to piggyback on developments elsewhere. A number of standard protocols have been, or are being, developed for communication between Internet access clients and servers. These include ftp, telnet, Gopher, Z39.50 and Prospero. In order to facilitate easy and transparent communication between tools more standards probably need to be developed. In the document interchange arena there is no current standard that allows for the creation of a multimedia document on one machine and its viewing or editing on a range of others. Adobe is proposing its Acrobat (Warnock [1992]) technology, based on Postscript and Multiple Master fonts, as a generic solution to the interchange of documents containing text, graphics and images. At present this technology has difficulties in supporting editing of received documents. Moreover, Adobe is not giving away the viewer software, providing a further barrier to the spread of Acrobat as a standard. The technological barriers to a true platform-independent multimedia document standard are considerable, but in today's heterogenous hardware and software environment such a standard is essential.
Despite all the above, the current situation is markedly better than only five years. Given the same rate of improvement (and every indication is that the rate is increasing, rather than decreasing), easy, transparent, powerful and rich Internet access technology is only a matter of time. Such technology will remove the barriers between user and information, and facilitate the use of the Internet as an information resource. This is something that all users can applaud, something that will help them tame the firehose of networked information, send them voyaging on the ocean of resources, and be their guide on their wanderings through the forest of services.
References
Berners-Lee, Tim et al. [1992], "World-Wide Web: The Information Universe." Electronic Networking: Research, Applications and Policy vol. 2, no. 1, pp. 52-58.Bowman, C. M., Danzig, P. B., and Schwartz, M. F. [1993], "Research Problems for Scalable Internet Resource Discovery", Proc. INET '93.
December, John [1993a], Internet-Tools (release 1.19), 24 Jul 1993. Available via anonymous ftp from ftp.rpi.edu, filed as pub/communications/internet-tools.
December, John [1993b], personal email to author, October 3, 1993.
Deutsch, Peter [1992], "Resource Discovery in an Internet Environment-- The Archie Approach." Electronic Networking: Research, Applications and Policy 2, no. 1, pp. 45-51.
Foster, Jill, Brett, George, and Deutsch, Peter [1993], A Status Report on Networked Information Retrieval: Tools and Groups, Draft version 4.1, Joint IETF/RARE/CNI Networked Information Retrieval - Working Group (NIR-WG). Latest version available via anonymous ftp to mailbase.ac.uk as file: /pub/nir/nir.status.report. (While draft internet reports should not generally be referred to, there is no other way to reference this report).
Kahle, Brewster et al. [1992], "Wide Area Information Servers: An Executive Information System for Unstructured Files." Electronic Networking: Research, Applications and Policy vol. 2, no. 1, pp. 59-68.
Lynch, C. A., and Preston, C. M. [1992], "Describing and Classifying Networked Information Resources", Electronic Networking, Vol. 2, No. 1, Spring, pp. 13-23.
Neuman, B. Clifford [1992], "Prospero: A Tool for Organizing Internet Resources", Electronic Networking: Research, Applications and Policy, 2 (1), Spring.
Neuman, B. Clifford, and Augart, Steven Seger [1993], "Prospero: A Base for Building Information Infrastructure", Proc. INET '93.
Obraczka, K., Danzig, P. B., and Li, S. [1993], "Internet Resource Discovery Services", IEEE Computer, September, pp. 8 - 22.
Scott, Peter. [1992], "Using HYTELNET to Access Internet Resources." The Public-Access Computer Systems Review vol. 3, no. 4, pp. 15-21. To retrieve this file, send the following e-mail message to LISTSERV@UHUPVM1.UH.EDU : GET SCOTT PRV3N4 F=MAIL.
Schwartz, M. F., Emtage, A., Kahle, B. and Neuman, B. C. [1992], "A Comparison of Internet Resource Discovery Approaches", Computing Systems, Vol. 5, No. 4, Fall, pp. 461 - 493.
Warnock, J. [1992], "The new age of documents", Byte, June 1992, pp. 257 - 260.
Wiggins, Rich. [1993], "The University of Minnesota's Internet Gopher System: A Tool for Accessing Network-Based Electronic Information." The Public-Access Computer Systems Review vol. 4, no. 2, pp. 4-60. To retrieve this file, send the following e-mail messages to LISTSERV@UHUPVM1.UH.EDU: GET WIGGINS1 PRV4N2 F=MAIL and GET WIGGINS2 PRV4N2 F=MAIL.
Yanoff, Scott [1993], Special Internet Connections List, posted periodically to alt.internet.services. Finger yanoff@csd4.csd.uwm.edu for more information.
[1] The term Internet is used here to refer specifically to the Internet proper, and does not include UUCP, BITNET, Fido and the like. Although these other networks provide a range of similar functions, these functions are implemented using different tools. This paper will concentrate on tools that assume or use TCP/IP as their underlying protocol.
[2] For more on the problems of describing networked information resources, please refer to Lynch and Preston [1992]. For more on the problems of discovering internet resources, refer to Bowman et. al. [1993].
[3] This paper will not attempt to discuss the entire range of Internet access tools. Some have narrow application are infrequently used, or have been superceded. The focus will be on the mainstream tools that most users will be familiar with and/or have access to.
[4] Jargon borrowed, somewhat loosely and with apologies where appropriate, from the fields of entity-relationship modelling and data communications respectively.
[5] Some of these are MIME (Multimedia Internet Mail Extensions), Adobe's Acrobat, GIF (Graphics Interchange Format) among others.
[6] Ftp also allows the user to put files from the local machine to a remote location - this function clearly does not belong under retrieval. However, the vast majority of ftp users only use the retrieval function.
[7] Any additions and corrections would be gratefully accepted. Contact information for the author is on the first page of this paper.
ÿ